https://en.wikipedia.org/wiki/Consistent_Overhead_Byte_Stuffing
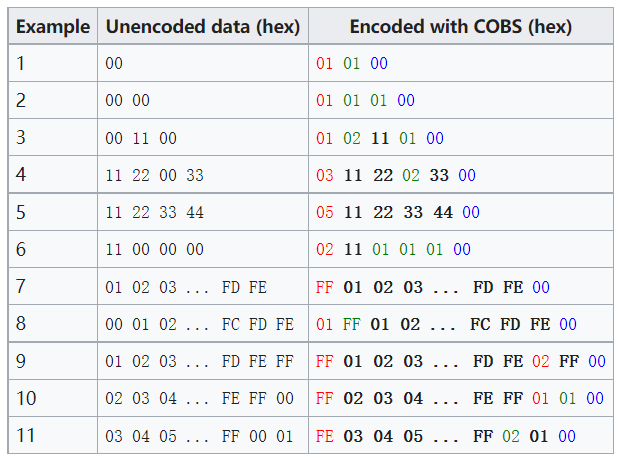
以modbus rtu通信为例,一般是3.5字符作为帧间隔区分,而使用COBS就不需要这样了,他是将范围 [0,255] 内的任意字节字符串转换为 [1,255] 范围内的字节。从数据中消除所有0,现在可以使用0来明确标记转换后数据的结束
.

[C] 纯文本查看 复制代码 #include <stddef.h>
#include <stdint.h>
#include <assert.h>
/** COBS encode data to buffer
@param data Pointer to input data to encode
@param length Number of bytes to encode
@param buffer Pointer to encoded output buffer
@return Encoded buffer length in bytes
@note Does not output delimiter byte
*/
size_t cobsEncode(const void *data, size_t length, uint8_t *buffer)
{
assert(data && buffer);
uint8_t *encode = buffer; // Encoded byte pointer
uint8_t *codep = encode++; // Output code pointer
uint8_t code = 1; // Code value
for (const uint8_t *byte = (const uint8_t *)data; length--; ++byte)
{
if (*byte) // Byte not zero, write it
*encode++ = *byte, ++code;
if (!*byte || code == 0xff) // Input is zero or block completed, restart
{
*codep = code, code = 1, codep = encode;
if (!*byte || length)
++encode;
}
}
*codep = code; // Write final code value
return (size_t)(encode - buffer);
}
/** COBS decode data from buffer
@param buffer Pointer to encoded input bytes
@param length Number of bytes to decode
@param data Pointer to decoded output data
@return Number of bytes successfully decoded
@note Stops decoding if delimiter byte is found
*/
size_t cobsDecode(const uint8_t *buffer, size_t length, void *data)
{
assert(buffer && data);
const uint8_t *byte = buffer; // Encoded input byte pointer
uint8_t *decode = (uint8_t *)data; // Decoded output byte pointer
for (uint8_t code = 0xff, block = 0; byte < buffer + length; --block)
{
if (block) // Decode block byte
*decode++ = *byte++;
else
{
if (code != 0xff) // Encoded zero, write it
*decode++ = 0;
block = code = *byte++; // Next block length
if (!code) // Delimiter code found
break;
}
}
return (size_t)(decode - (uint8_t *)data);
}
| 








 发表于 2022-9-13 05:24:04
发表于 2022-9-13 05:24:04
 发表于 2022-9-13 08:05:23
发表于 2022-9-13 08:05:23


 楼主
楼主


{kind=link}
{kind=link}