- 1、嵌入式专题教程
- 2、Modbus主从协议栈
- 3、CANopen主从协议栈
- 4、J1939协议栈
- 5、USB上位机教程
- 6、RL-USB协议栈教程
- 7、ThreadX内核教程
- 8、ThreadX GUIX教程
- 9、ThreadX FileX教程
- 10、ThreadX NetXDUO网络教程
- 11、ThreadX USBX教程
- 12、RTX4操作系统教程
- 13、RTX5操作系统教程
- 14、uCOS-III操作系统教程
- 15、FreeRTOS操作系统教程
- 16、第1版RL-TCPnet史诗级网络教程
- 17、第2版RL-TCPnet V7.X网络和物联网教程
- 18、LwIP网络教程,配套RTX5和FreeRTOS两版
- 19、双网口教程,单网线协议栈同时管理两个网口
- 20、第2版65章2076页史诗级emWin教程
- 21、第3版emWin教程,配合AppWizard
- 22、STM32H7用户手册,重在BSP驱动包设计
- 23、STM32F4用户手册,重在BSP驱动包设计
- 24、第1版DSP数字信号处理教程
- 25、第2版DSP数字信号处理和CMSIS-NN神经网络教程
- 1、STM32H743XIH6开发板
- 2、STM32F429BIT6开发板
- 3、STM32F407IGT6开发板
- 4、STM32F103ZET6开发板
- 5、STM8S-EK1开发板
- 6、STM8S-EK2开发板
- 7、STM32-P01工控板
- 8、STM32-P02工控板
- 9、多款无线IO控制器
- 10、DX-Pro逻辑分析仪
- 11、ADC,DAC,TFT,传感器,无线等模块









 发表于 2021-11-26 01:54:50
发表于 2021-11-26 01:54:50
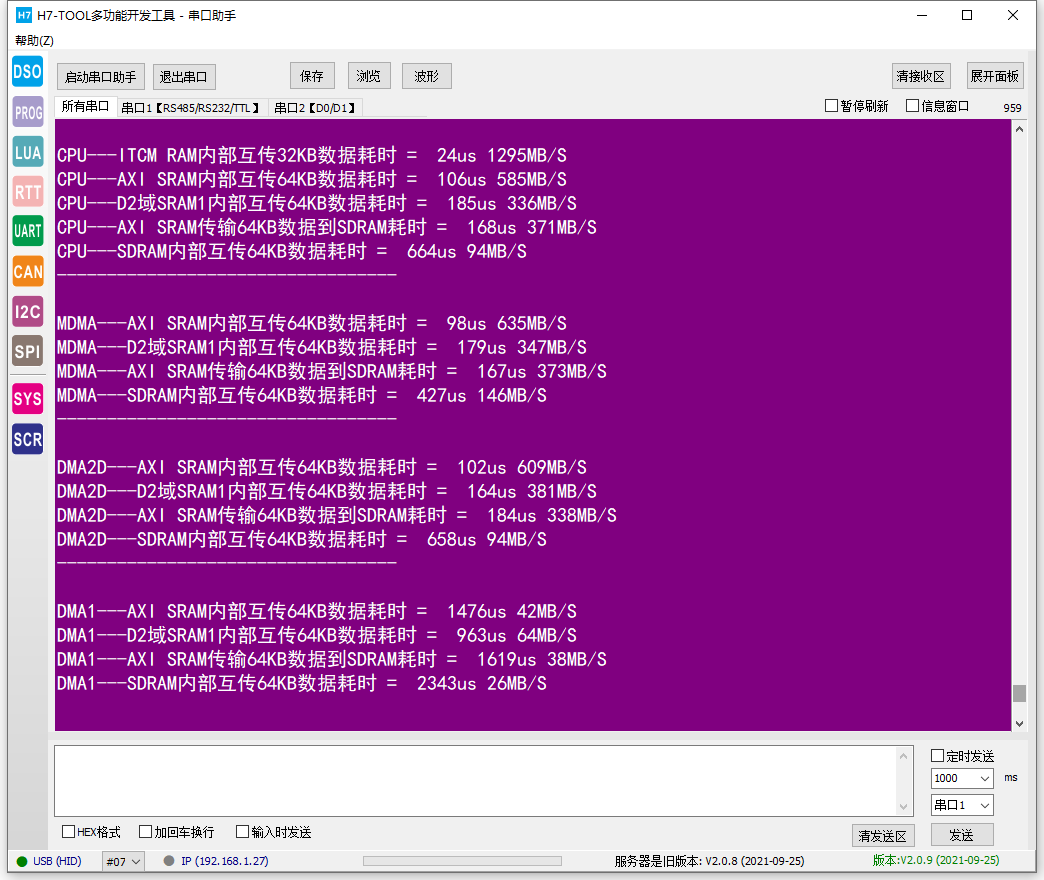
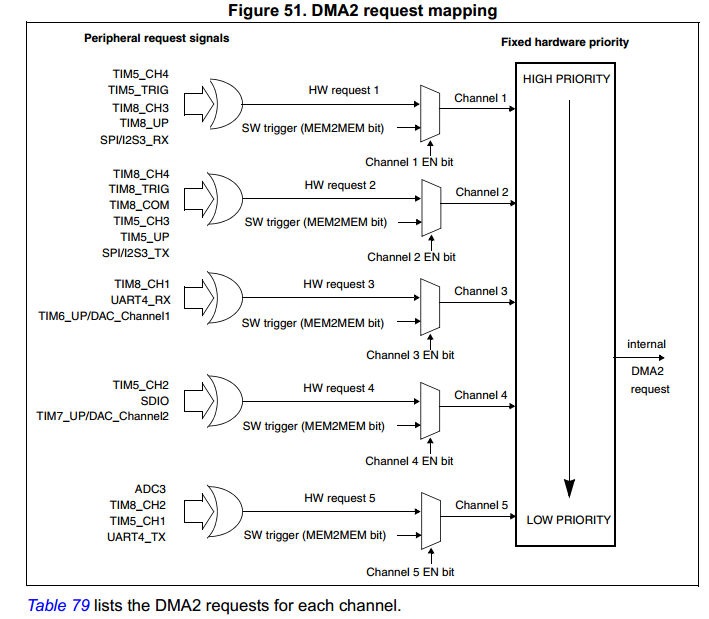
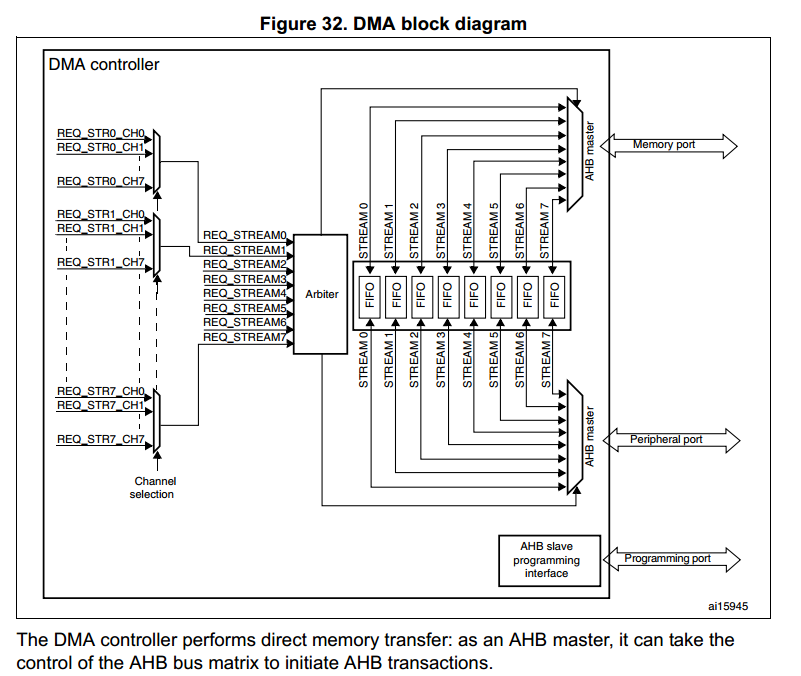
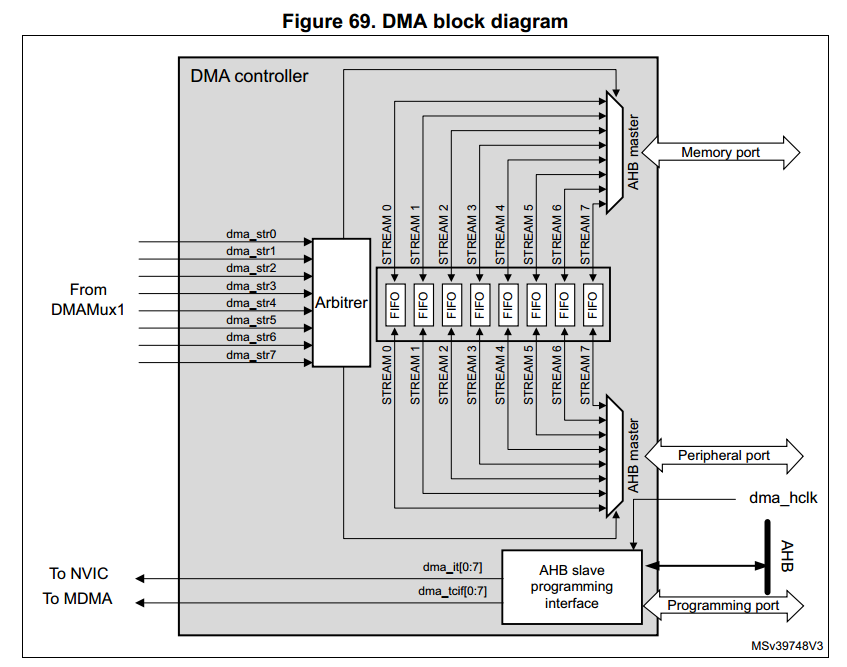
 楼主
楼主 发表于 2021-11-26 07:52:13
发表于 2021-11-26 07:52:13


 ,stm32的dma需要等待上一个请求的数据量全部传完了才会响应下一个请求,响应新请求的时候又会根据优先级来响应
,stm32的dma需要等待上一个请求的数据量全部传完了才会响应下一个请求,响应新请求的时候又会根据优先级来响应
{kind=link}
{kind=link}